Chapter 6 Introduction to Statistics
6.1 Summary Statistics
6.1.1 Measures of center
- Mean: sum of all the data points divided by the total number of data points.
- Median: middle value of the dataset where 50% of the data is less than the median, and 50% of the data is greater than the median.
- Mode: most frequent value.
You’ll be working with the 2018 Food Carbon Footprint Index from nu3. The food_consumption dataset contains information about the kilograms of food consumed per person per year in each country in each food category (consumption) as well as information about the carbon footprint of that food category (co2_emissions) measured in kilograms of carbon dioxide, or CO2, per person per year in each country.
#library package
library(tidyverse)
# Load dataset
food_consumption <- read_rds("data/food_consumption.rds")When you want to compare summary statistics between groups, it’s much easier to do a group_by() and one summarize() instead of filtering and calling the same functions multiple times.
food_consumption %>%
# Filter for Belgium and USA
filter(country %in% c("Belgium", "USA")) %>%
# Group by country
group_by(country) %>%
# Get mean_consumption and median_consumption
summarize(mean_consumption = mean(consumption),
median_consumption = median(consumption))## # A tibble: 2 × 3
## country mean_consumption median_consumption
## <chr> <dbl> <dbl>
## 1 Belgium 42.1 12.6
## 2 USA 44.6 14.66.1.1.1 Mean vs. median
Visualizing
Right-skewed
food_consumption %>%
# Filter for rice food category
filter(food_category == "rice") %>%
# Create histogram of co2_emission
ggplot(aes(x = co2_emission)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better
## value with `binwidth`.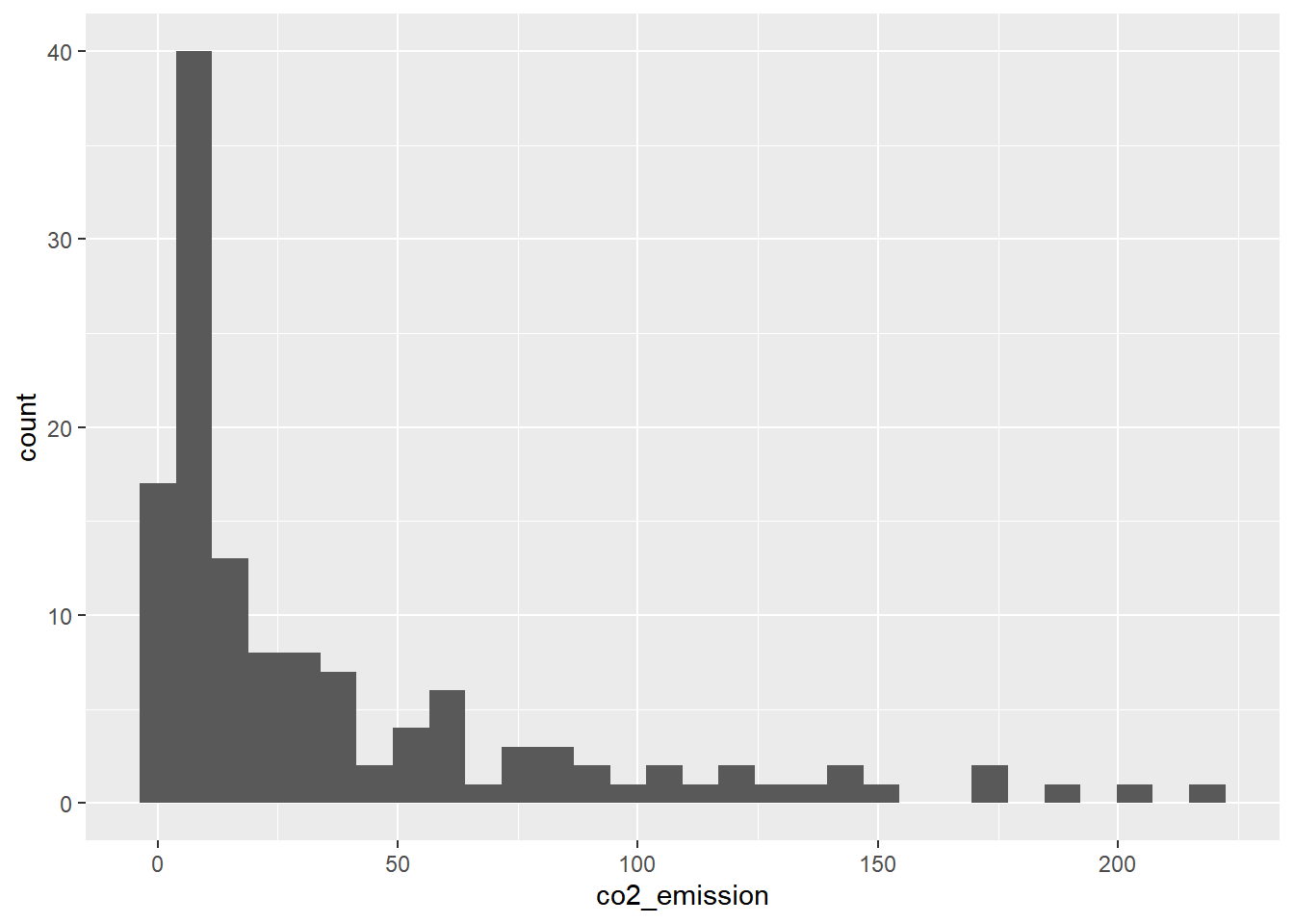
Central tendency
Given the skew of this data, the measure median of central tendency best summarizes the kilograms of CO2 emissions per person per year for rice.
food_consumption %>%
# Filter for rice food category
filter(food_category == "rice") %>%
# Get mean_co2 and median_co2
summarize(mean_co2 = mean(co2_emission),
median_co2 = median(co2_emission))## # A tibble: 1 × 2
## mean_co2 median_co2
## <dbl> <dbl>
## 1 37.6 15.26.1.2 Measures of spread
Useful functions:
Variance = var()
Standard Deviation = sd()
Quartiles = quantile() / quantile(data, probs = ())
Mean absolute deviation = mean(abs(dist))
Boxplots use quartiles
6.1.2.1 Quartiles, quantiles, and quintiles
Quantiles are a great way of summarizing numerical data since they can be used to measure center and spread, as well as to get a sense of where a data point stands in relation to the rest of the dataset.
# Calculate the quartiles of co2_emission
quantile(food_consumption$co2_emission)## 0% 25% 50% 75% 100%
## 0.0000 5.2100 16.5300 62.5975 1712.0000# Calculate the six quantiles that split up the data into 5 pieces (quintiles) of the co2_emission column
quantile(food_consumption$co2_emission, probs = seq(0, 1, 0.2))## 0% 20% 40% 60% 80% 100%
## 0.000 3.540 11.026 25.590 99.978 1712.000# Calculate the eleven quantiles of co2_emission that split up the data into ten pieces (deciles)
quantile(food_consumption$co2_emission, probs = seq(0, 1, 0.1))## 0% 10% 20% 30% 40% 50% 60% 70%
## 0.000 0.668 3.540 7.040 11.026 16.530 25.590 44.271
## 80% 90% 100%
## 99.978 203.629 1712.0006.1.2.2 Variance & standard deviation
Variance and standard deviation are two of the most common ways to measure the spread of a variable, especially when making predictions.
# Calculate variance and sd of co2_emission for each food_category
food_consumption %>%
group_by(food_category) %>%
summarize(var_co2 = var(co2_emission),
sd_co2 = sd(co2_emission))## # A tibble: 11 × 3
## food_category var_co2 sd_co2
## <fct> <dbl> <dbl>
## 1 beef 88748. 298.
## 2 eggs 21.4 4.62
## 3 fish 922. 30.4
## 4 lamb_goat 16476. 128.
## 5 dairy 17672. 133.
## 6 nuts 35.6 5.97
## 7 pork 3095. 55.6
## 8 poultry 245. 15.7
## 9 rice 2281. 47.8
## 10 soybeans 0.880 0.938
## 11 wheat 71.0 8.43# Plot food_consumption with co2_emission on x-axis
ggplot(food_consumption, aes(x = co2_emission)) +
# Create a histogram
geom_histogram() +
# Create a separate sub-graph for each food_category
facet_wrap(~ food_category)## `stat_bin()` using `bins = 30`. Pick better
## value with `binwidth`.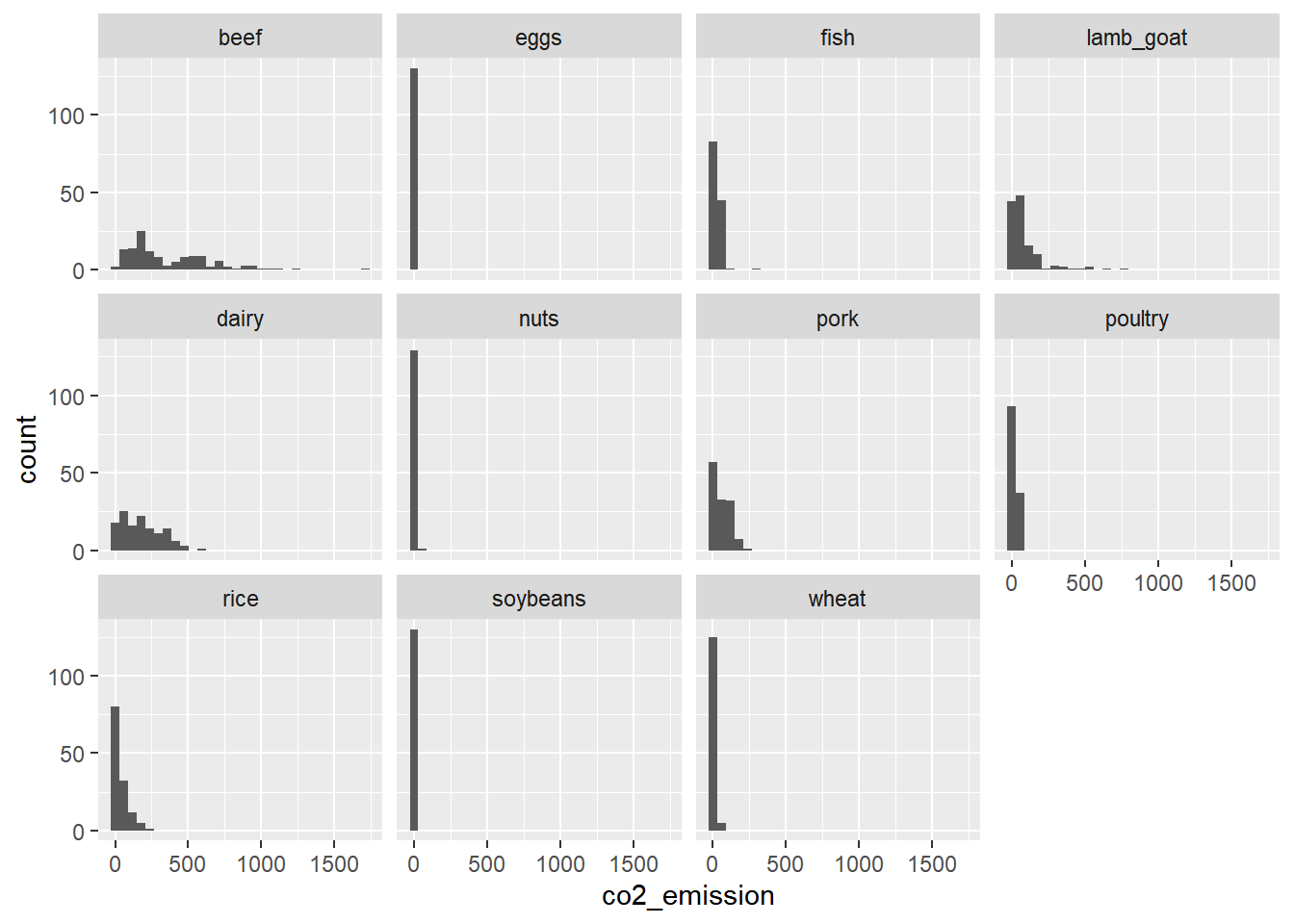
Beef has the biggest amount of variation in its CO2 emissions, while eggs, nuts, and soybeans have relatively small amounts of variation.
6.1.2.3 Finding outliers using IQR
Outliers can have big effects on statistics like mean, as well as statistics that rely on the mean, such as variance and standard deviation. Interquartile range, or IQR, is another way of measuring spread that’s less influenced by outliers. IQR is also often used to find outliers. If a value is less than Q1−1.5×IQR or greater than Q3+1.5×IQR, it’s considered an outlier. In fact, this is how the lengths of the whiskers in a ggplot2 box plot are calculated.
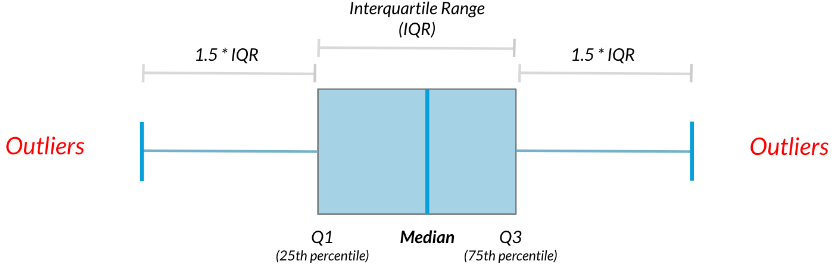
IQR = Q3 - Q1
Outlier = data < Q1 − 1.5 × IQR or data > Q3 + 1.5 × IQR
# Calculate total co2_emission per country: emissions_by_country
emissions_by_country <- food_consumption %>%
group_by(country) %>%
summarize(total_emission = sum(co2_emission))
# Compute the first and third quartiles and IQR of total_emission
q1 <- quantile(emissions_by_country$total_emission, 0.25); q1## 25%
## 446.66q3 <- quantile(emissions_by_country$total_emission, 0.75); q3## 75%
## 1111.152iqr <- q3 - q1; iqr## 75%
## 664.4925# Calculate the lower and upper cutoffs for outliers
lower <- q1 - 1.5 * iqr
upper <- q3 + 1.5 * iqr
# Filter emissions_by_country to find outliers
emissions_by_country %>%
filter(total_emission < lower | total_emission > upper)## # A tibble: 1 × 2
## country total_emission
## <chr> <dbl>
## 1 Argentina 2172.6.2 Random Numbers and Probability
6.2.1 Chances
6.2.1.1 Calculating probabilities
You want to randomly select a few of the deals that he’s worked on over the past year so that you can look at them more deeply. Before you start selecting deals, you’ll first figure out what the chances are of selecting certain deals.
# Load dataset
amir_deals <- read_rds("data/seller_1.rds")
amir_deals %>%
# Count the deals for each product
count(product) %>%
# Calculate probability of picking a deal with each product
mutate(prob = n / sum(n))## product n prob
## 1 Product A 23 0.12921348
## 2 Product B 62 0.34831461
## 3 Product C 15 0.08426966
## 4 Product D 40 0.22471910
## 5 Product E 5 0.02808989
## 6 Product F 11 0.06179775
## 7 Product G 2 0.01123596
## 8 Product H 8 0.04494382
## 9 Product I 7 0.03932584
## 10 Product J 2 0.01123596
## 11 Product N 3 0.016853936.2.1.2 Sampling deals
With or without replacement?
With replacement: 抽出後放回, events are independent, sample_n(n, replace = T)
Flipping a coin 3 times
Rolling a die twice
Without replacement: 抽出後不放回, events are dependent, sample_n()
From a deck of cards, dealing 3 players 7 cards each
Randomly picking 3 people to work on the weekend from a group of 20 people
Randomly selecting 5 products from the assembly line to test for quality assurance
Now it’s time to randomly pick five deals so that you can reach out to each customer and ask if they were satisfied with the service they received. You’ll try doing this both with and without replacement.
Additionally, you want to make sure this is done randomly and that it can be reproduced in case you get asked how you chose the deals, so you’ll need to set the random seed set.seed() before sampling.
In this case, without replacement sampling would be suitable.
# Set random seed to 31
set.seed(31)
# Sample 5 deals without replacement
amir_deals %>%
sample_n(5)## product client status amount num_users
## 1 Product D Current Lost 3086.88 55
## 2 Product C Current Lost 3727.66 19
## 3 Product D Current Lost 4274.80 9
## 4 Product B Current Won 4965.08 9
## 5 Product A Current Won 5827.35 50# Sample 5 deals with replacement
amir_deals %>%
sample_n(5, replace = TRUE)## product client status amount num_users
## 1 Product A Current Won 6010.04 24
## 2 Product B Current Lost 5701.70 53
## 3 Product D Current Won 6733.62 27
## 4 Product F Current Won 6780.85 80
## 5 Product C Current Won -539.23 116.2.2 Discrete distributions
6.2.2.1 Creating a probability distribution
A new restaurant opened a few months ago, and the restaurant’s management wants to optimize its seating space based on the size of the groups that come most often. On one night, there are 10 groups of people waiting to be seated at the restaurant, but instead of being called in the order they arrived, they will be called randomly. In this exercise, you’ll investigate the probability of groups of different sizes getting picked first.
# create restaurant_groups dataset
group_id <- LETTERS[seq(1, 10)]
group_size <- c(2, 4, 6, 2, 2, 2, 3, 2, 4, 2)
restaurant_groups <- data.frame(group_id, group_size); restaurant_groups## group_id group_size
## 1 A 2
## 2 B 4
## 3 C 6
## 4 D 2
## 5 E 2
## 6 F 2
## 7 G 3
## 8 H 2
## 9 I 4
## 10 J 2# Create a histogram of group_size
ggplot(restaurant_groups, aes(x = group_size)) +
geom_histogram(bins = 5)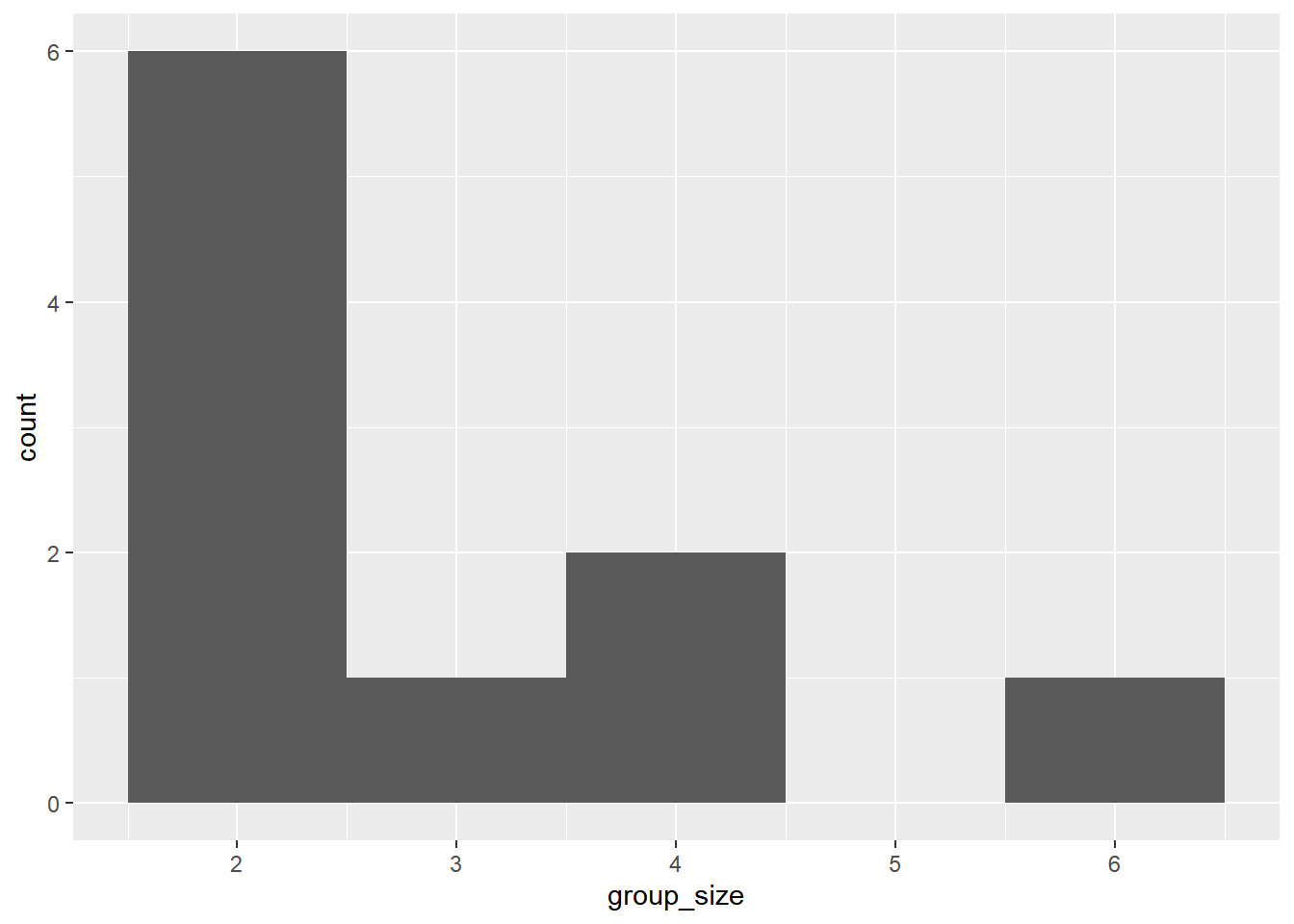
# Create probability distribution
size_distribution <- restaurant_groups %>%
# Count number of each group size
count(group_size) %>%
# Calculate probability
mutate(probability = n / sum(n))
size_distribution## group_size n probability
## 1 2 6 0.6
## 2 3 1 0.1
## 3 4 2 0.2
## 4 6 1 0.1# Calculate expected group size
expected_val <- sum(size_distribution$group_size * size_distribution$probability)
expected_val## [1] 2.9# Calculate probability of picking group of 4 or more
size_distribution %>%
# Filter for groups of 4 or larger
filter(group_size >= 4) %>%
# Calculate prob_4_or_more by taking sum of probabilities
summarize(prob_4_or_more = sum(probability))## prob_4_or_more
## 1 0.36.2.3 Continuous distributions
The sales software used at your company is set to automatically back itself up, but no one knows exactly what time the back-ups happen. It is known, however, that back-ups happen exactly every 30 minutes. Amir comes back from sales meetings at random times to update the data on the client he just met with. He wants to know how long he’ll have to wait for his newly-entered data to get backed up.
# Min and max wait times for back-up that happens every 30 min
min <- 0
max <- 30
# Calculate probability of waiting less than 5 mins
prob_less_than_5 <- punif(5, min = 0, max = 30)
prob_less_than_5## [1] 0.1666667# Calculate probability of waiting more than 5 mins
prob_greater_than_5 <- punif(5, min = 0, max = 30, lower.tail = FALSE)
prob_greater_than_5## [1] 0.8333333# Calculate probability of waiting 10-20 mins
prob_between_10_and_20 <- punif(20, min = 0, max = 30) - punif(10, min = 0, max = 30)
prob_between_10_and_20## [1] 0.3333333To give Amir a better idea of how long he’ll have to wait, you’ll simulate Amir waiting 1000 times and create a histogram to show him what he should expect.
Notice: simulation_nb, runif
# Create dataset, normal distribution
wait_times <- data.frame(simulation_nb = 1:1000)
# Set random seed to 334
set.seed(334)
# Generate 1000 wait times between 0 and 30 mins, save in time column
wait_times %>%
mutate(time = runif(1000, min = 0, max = 30)) %>%
# Create a histogram of simulated times
ggplot(aes(x = time)) +
geom_histogram(bins = 30)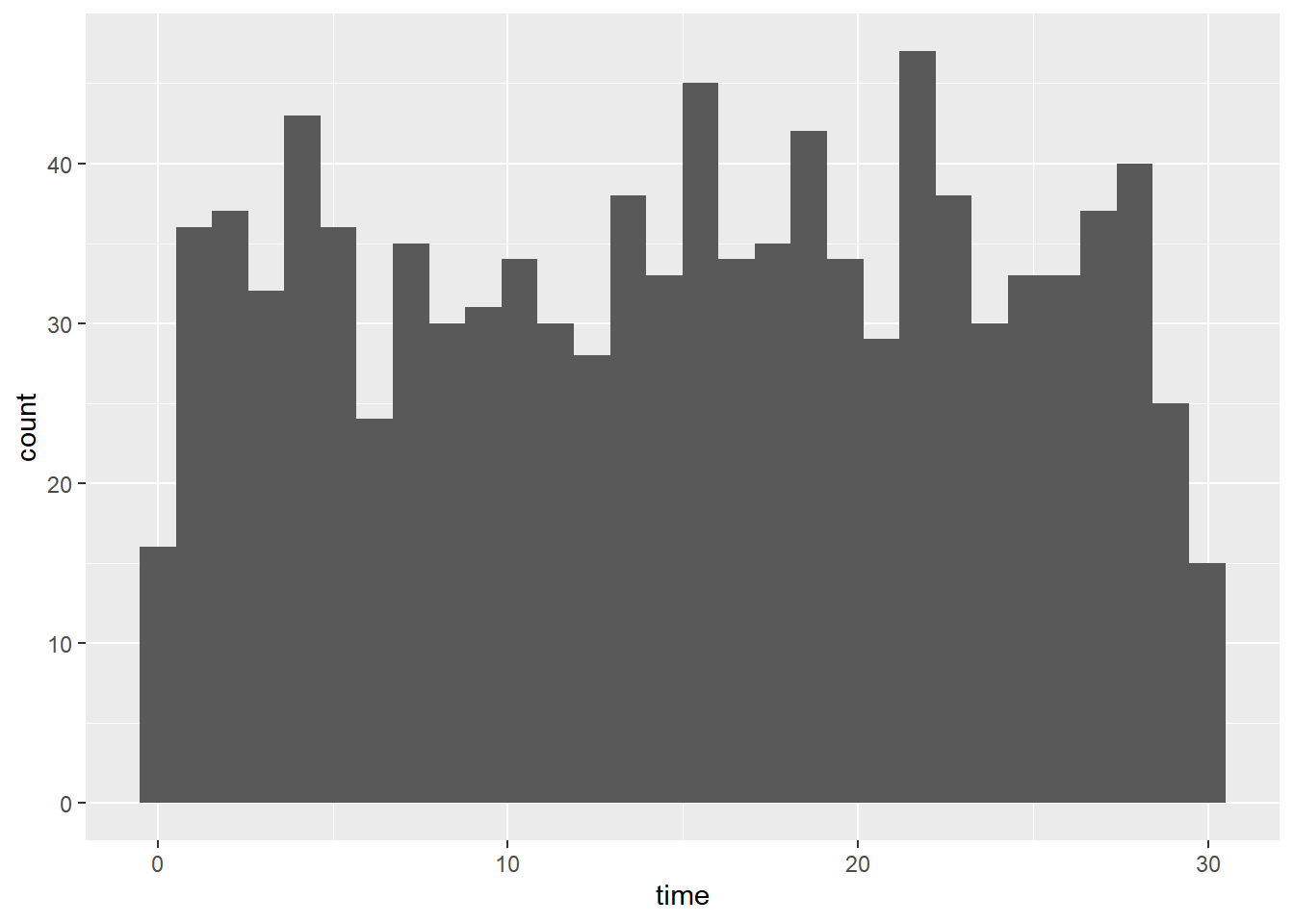
6.2.4 Binomial distribution
Probability distribution of the number of successes in a sequence of independent trials.
n: total number of trials
p: probability of success
Binary outcomes:
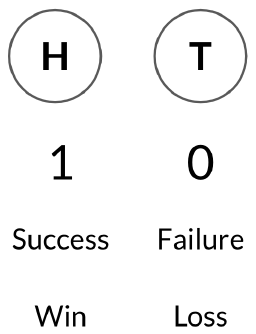
rbinom(n of trials, n of coins, probability of heads/success)
# 1 = head, 0 = tail
# A single flip
rbinom(1, 1, 0.5)
# 8 flips of 1 coin with 50% chance of success
rbinom(8, 1, 0.5)
# 10 flips of 3 coin with 25% chance of success
rbinom(10, 3, 0.25)
# p(head = n)
dbinom(num heads, num trials, prob of heads)
# p(head >= or <= n)
pbinom(num heads, num trials, prob of heads, lower.tail = T or F)6.2.4.1 Simulating
Assume that Amir usually works on 3 deals per week, and overall, he wins 30% of deals he works on. Each deal has a binary outcome: it’s either lost, or won, so you can model his sales deals with a binomial distribution. In this exercise, you’ll help Amir simulate a year’s worth of his deals so he can better understand his performance.
# Set random seed to 10
set.seed(10)
# Simulate a single deal
rbinom(1, 1, 0.3)## [1] 0# Simulate 1 week of 3 deals
rbinom(1, 3, 0.3)## [1] 0# Simulate 52 weeks of 3 deals
deals <- rbinom(52, 3, 0.3)
# Calculate mean deals won per week
mean(deals)## [1] 0.80769236.2.4.2 Calculating binomial probabilities
Just as in the last exercise, assume that Amir wins 30% of deals. He wants to get an idea of how likely he is to close a certain number of deals each week. In this exercise, you’ll calculate what the chances are of him closing different numbers of deals using the binomial distribution.
# What's the probability that Amir closes all 3 deals in a week?
# Probability of closing 3 out of 3 deals
dbinom(3, 3, 0.3)## [1] 0.027# What's the probability that Amir closes 1 or fewer deals in a week?
# Probability of closing <= 1 deal out of 3 deals
pbinom(1, 3, 0.3)## [1] 0.784# What's the probability that Amir closes more than 1 deal?
# Probability of closing > 1 deal out of 3 deals
pbinom(1, 3, 0.3, lower.tail = F)## [1] 0.2161 - pbinom(1, 3, 0.3)## [1] 0.2166.2.4.3 Expected value
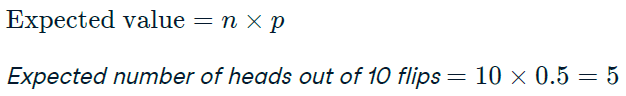
Now Amir wants to know how many deals he can expect to close each week if his win rate changes. Luckily, you can use your binomial distribution knowledge to help him calculate the expected value in different situations.
# Expected number won with 30% win rate
won_30pct <- 3 * 0.3
won_30pct## [1] 0.9# Expected number won with 25% win rate
won_25pct <- 3 * 0.25
won_25pct## [1] 0.75# Expected number won with 35% win rate
won_35pct <- 3 * 0.35
won_35pct## [1] 1.056.3 More Distributions & Central Limit Theorem
6.3.1 Normal distribution
Areas under the normal distribution
- 68% falls within 1 standard deviation
- 95% falls within 2 standard deviations
- 99.7% falls within 3 standard deviations
Get percentage or value
# Percent
pnorm(value, mean = , sd = , lower.tail = )
# Value
qnorm(probability, mean = , sd = , lower.tail = )Generating random numbers
# Generate 10 random number
rnorm(10, mean = , sd = )6.3.1.1 Visualing distribution
Since each deal Amir worked on (both won and lost) was different, each was worth a different amount of money. These values are stored in the amount column of amir_deals As part of Amir’s performance review, you want to be able to estimate the probability of him selling different amounts, but before you can do this, you’ll need to determine what kind of distribution the amount variable follows.
# Histogram of amount with 10 bins
ggplot(amir_deals, aes(x = amount)) +
geom_histogram(bins = 10)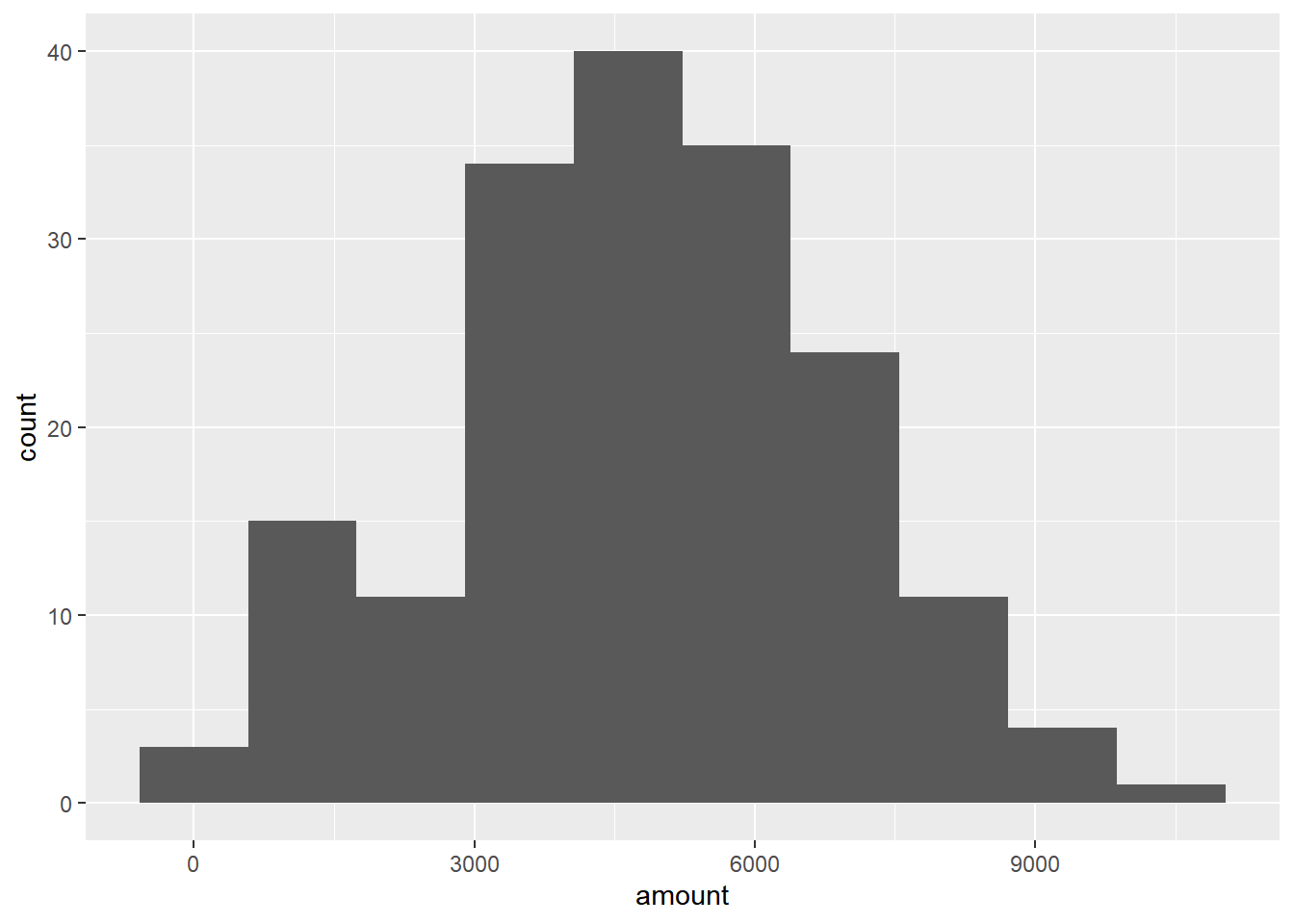
6.3.1.2 Probabilities from the normal distribution
Since each deal Amir worked on (both won and lost) was different, each was worth a different amount of money. These values are stored in the amount column of amir_deals and follow a normal distribution with a mean of 5000 dollars and a standard deviation of 2000 dollars. As part of his performance metrics, you want to calculate the probability of Amir closing a deal worth various amounts.
# Probability of deal < 7500
pnorm(7500, mean = 5000, sd = 2000)## [1] 0.8943502# Probability of deal > 1000
pnorm(1000, mean = 5000, sd = 2000, lower.tail = FALSE)## [1] 0.9772499# Probability of deal between 3000 and 7000
pnorm(7000, mean = 5000, sd = 2000) - pnorm(3000, mean = 5000, sd = 2000)## [1] 0.6826895# Calculate amount that 75% of deals will be more than
qnorm(0.75, mean = 5000, sd = 2000, lower.tail = F)## [1] 3651.026.3.1.3 Simulating under new conditions
The company’s financial analyst is predicting that next quarter, the worth of each sale will increase by 20% and the volatility, or standard deviation, of each sale’s worth will increase by 30%. To see what Amir’s sales might look like next quarter under these new market conditions, you’ll simulate new sales amounts using the normal distribution and store these in the new_sales data frame.
# Calculate new average amount
new_mean <- 5000 * 1.2
# Calculate new standard deviation
new_sd <- 2000 * 1.3
# Simulate 36 sales
new_sales <- data.frame(sale_num = 1:36)
new_sales <- new_sales %>%
mutate(amount = rnorm(36, mean = new_mean, sd = new_sd)); new_sales## sale_num amount
## 1 1 3732.387
## 2 2 5735.421
## 3 3 5340.171
## 4 4 1180.275
## 5 5 5797.340
## 6 6 8518.272
## 7 7 6480.807
## 8 8 2412.147
## 9 9 2267.663
## 10 10 6941.427
## 11 11 1426.374
## 12 12 5156.186
## 13 13 4305.936
## 14 14 8825.034
## 15 15 4017.383
## 16 16 3845.477
## 17 17 8169.632
## 18 18 3484.105
## 19 19 5925.080
## 20 20 6604.565
## 21 21 5216.857
## 22 22 4238.202
## 23 23 7703.592
## 24 24 4958.342
## 25 25 5130.153
## 26 26 9556.680
## 27 27 11558.194
## 28 28 7315.130
## 29 29 8044.490
## 30 30 3654.249
## 31 31 7385.532
## 32 32 4320.675
## 33 33 6756.567
## 34 34 2782.254
## 35 35 4813.942
## 36 36 3841.161# Create histogram with 10 bins
ggplot(new_sales, aes(x = amount)) +
geom_histogram(bins = 10)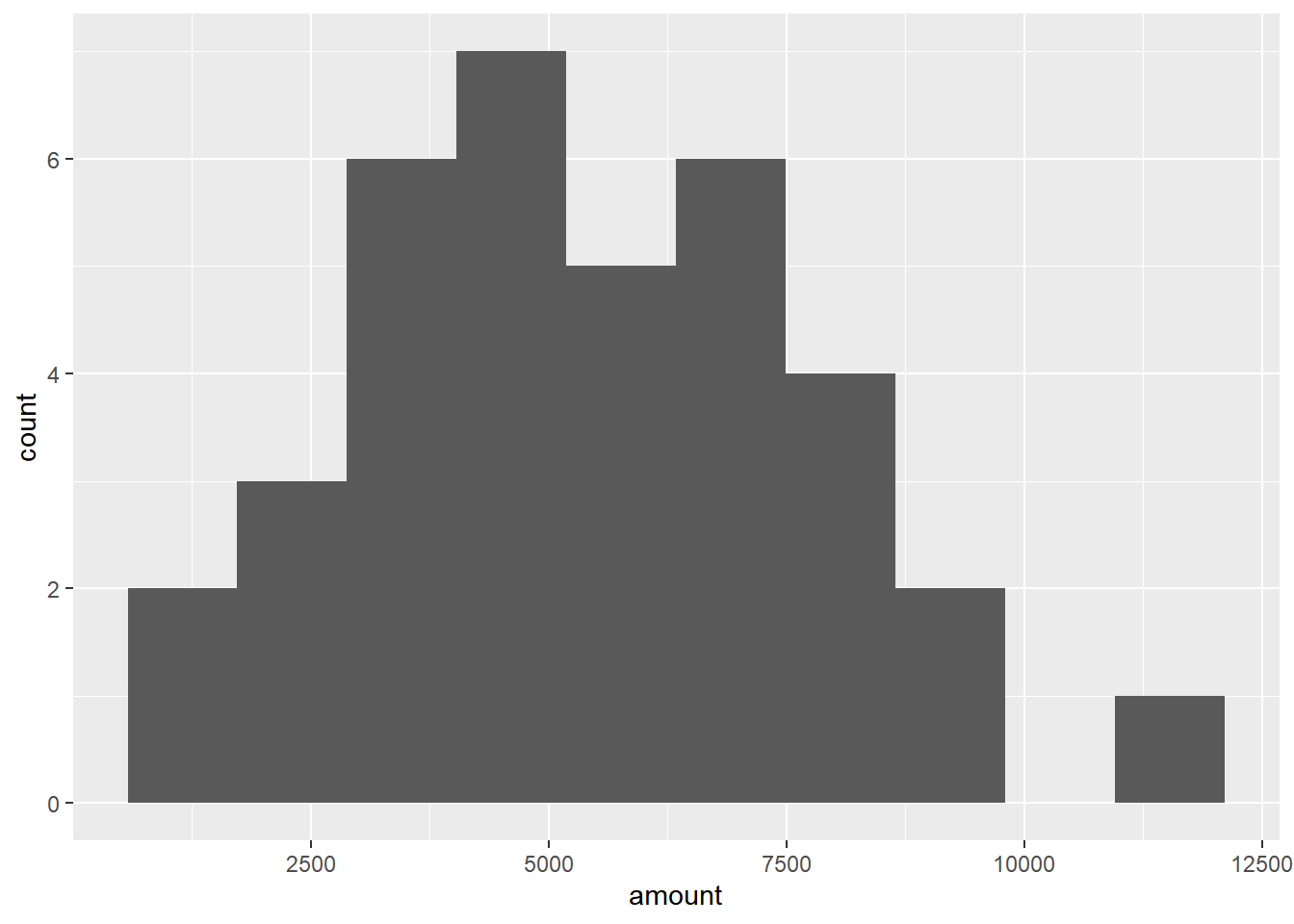
6.3.2 Central limit theorem
The sampling distribution of a statistic becomes closer to the normal distribution as the number of trials increases.
It’s important to note that the central limit theorem only applies when samples are taken randomly and are independent.
Regardless of the shape of the distribution you’re taking sample means from, the central limit theorem will apply if the sampling distribution contains enough sample means.
sample() works the same way as sample_n(), except it samples from a vector instead of a data frame.
sample(vector to sample from, size of the sample, replace = T/F)replicate() use to repeat doing the same thing.
replicate(num of replication, run code)6.3.2.1 The CLT in action
The central limit theorem states that a sampling distribution of a sample statistic approaches the normal distribution as you take more samples, no matter the original distribution being sampled from.
In this exercise, you’ll focus on the sample mean and see the central limit theorem in action while examining the num_users column of amir_deals more closely, which contains the number of people who intend to use the product Amir is selling.
# Set seed to 104
set.seed(104)
# Sample 20 num_users from amir_deals and take mean
sample(amir_deals$num_users, size = 20, replace = TRUE) %>%
mean()## [1] 30.35# Repeat the above 100 times
sample_means <- replicate(100, sample(amir_deals$num_users, size = 20, replace = TRUE) %>% mean())
# Create data frame for plotting
samples <- data.frame(mean = sample_means)
# Histogram of sample means
ggplot(samples, aes(x = mean)) +
geom_histogram(bins = 10)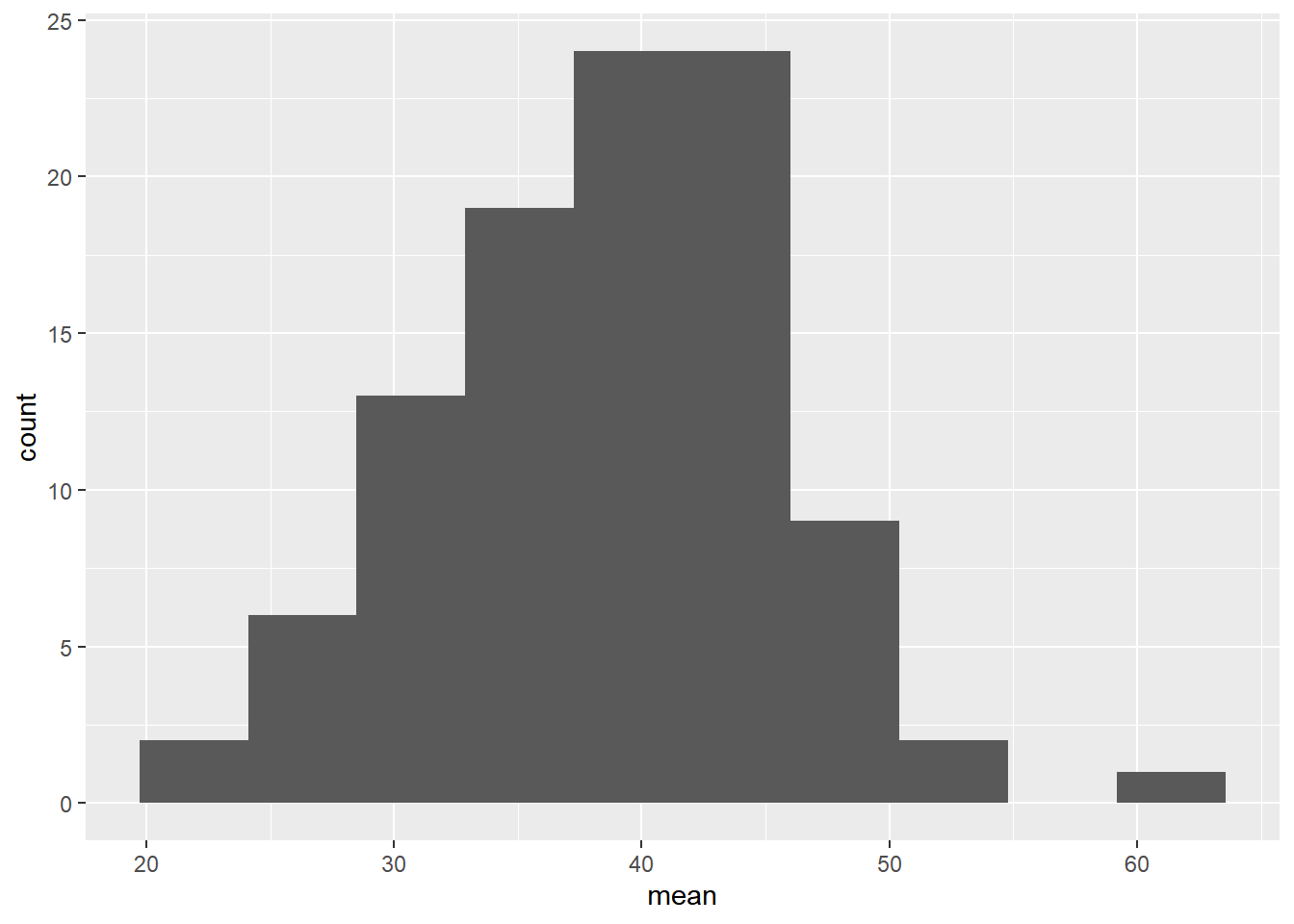
6.3.2.2 The mean of means
You want to know what the average number of users (num_users) is per deal, but you want to know this number for the entire company so that you can see if Amir’s deals have more or fewer users than the company’s average deal. The problem is that over the t year, the company has worked on more than ten thousand deals, so it’s not realistic to compile all the data. Instead, you’ll estimate the mean by taking several random samples of deals, since this is much easier than collecting data from everyone in the company.
# Load dataset
all_deals <- read.table(file = "data/all_deals.txt", header = TRUE)
# Set seed to 321
set.seed(321)
# Take 30 samples of 20 values of num_users, take mean of each sample
sample_means <- replicate(30, sample(all_deals$num_users, 20) %>% mean())
# Calculate mean of sample_means
mean(sample_means)## [1] 37.02667# Calculate mean of num_users in amir_deals
mean(amir_deals$num_users)## [1] 37.65169Amir’s average number of users is very close to the overall average, so it looks like he’s meeting expectations.
6.3.3 Poisson distribution
A Poisson process is a process where events appear to happen at a certain rate, but completely at random. Example:
- Number of people arriving at a restaurant per hour.
- Number of earthquakes in California per year.
The Poisson distribution describes the probability of some number of events happening over a fixed period of time.(discrete)
Lambda (λ): average number of events per time interval.(event)
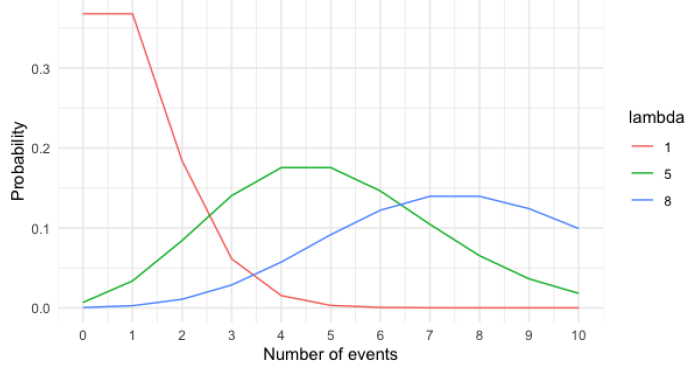
Notice: Lambda changes the shape of the distribution. But no matter what, the distribution’s peak is always at its lambda value.
Syntax:
Note that if you provide dpois() or ppois() with a non-integer, it returns 0 and throws a warning since the Poisson distribution only applies to integers.
# Probability of a single value
dpois(value, lambda = )
# Probability of less than or equal to
ppois(value, lambda = )
# Probability of greater than
ppois(value, lambda = , lower.tail = FALSE)
# Sampling from a Poisson distribution
rpois(num of sample, lambda = )6.3.3.1 Tracking lead responses
Your company uses sales software to keep track of new sales leads. It organizes them into a queue so that anyone can follow up on one when they have a bit of free time. Since the number of lead responses is a countable outcome over a period of time, this scenario corresponds to a Poisson distribution. On average, Amir responds to 4 leads each day. In this exercise, you’ll calculate probabilities of Amir responding to different numbers of leads.
# What's the probability that Amir responds to 5 leads in a day, given that he responds to an average of 4?
# Probability of 5 responses
dpois(5, lambda = 4)## [1] 0.1562935# Amir's coworker responds to an average of 5.5 leads per day. What is the probability that she answers 5 leads in a day?
# Probability of 5 responses from coworker
dpois(5, lambda = 5.5)## [1] 0.1714007# Probability of 2 or fewer responses
ppois(2, lambda = 4)## [1] 0.2381033# Probability of > 10 responses
ppois(10, lambda = 4, lower.tail = F)## [1] 0.0028397666.3.4 Exponential distribution
Probability of time between Poisson events. (continuous) Example:
- Probability of < 10 minutes between restaurant arrivals.
- Probability of 6-8 months between earthquakes.
Lambda (λ): rate
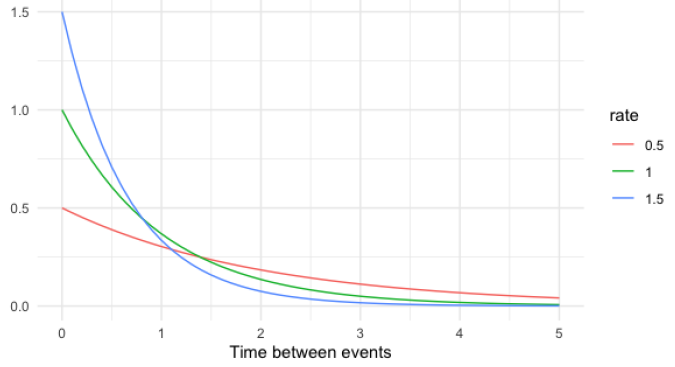
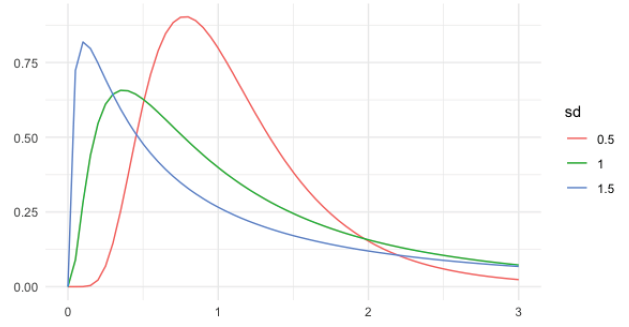
Notice: The rate(λ) affects the shape of the distribution and how steeply it declines.
Expected value of exponential distribution
- In terms of rate (Poisson): λ
- In terms of time (exponential): 1/λ
Syntax:
pexp(value, rate = )
# For example
# P (wait < 1 min)
pexp(1, rate = 0.5)
# P (wait > 4 min)
pexp(4, rate = 0.5, lower.tail = FALSE)
# P (1 min < wait < 4 min)
pexp(4, rate = 0.5) - pexp(1, rate = 0.5)6.3.4.1 Modeling time between leads
To further evaluate Amir’s performance, you want to know how much time it takes him to respond to a lead after he opens it. On average, it takes 2.5 hours for him to respond. In this exercise, you’ll calculate probabilities of different amounts of time passing between Amir receiving a lead and sending a response.
# 2.5 is the time expected value, which equal to 1/λ. So in order to get rate(λ), we have to 1 / 2.5 first. (1/λ = 2.5 > λ = 1/2.5)
# Probability response takes < 1 hour
pexp(1, rate = 1 / 2.5)## [1] 0.32968# Probability response takes > 4 hours
pexp(4, rate = 1 / 2.5, lower.tail = F)## [1] 0.2018965# Probability response takes 3-4 hours
pexp(4, rate = 1/2.5) - pexp(3, rate = 1/2.5)## [1] 0.09929769
6.4 Correlation and Experimental Design
6.4.1 Correlation
6.4.1.1 Visualizing relationships
To visualize relationships between two variables, we can use a scatterplot created using geom_point. We can add a linear trendline to the scatterplot using geom_smooth. We’ll set the method argument to “lm” to indicate that we want a linear trendline, and se to FALSE so that there aren’t error margins around the line.
ggplot(df, aes(x, y)) +
geom_point() +
# Adding a trendline
geom_smooth(method = "lm", se = FALSE)6.4.1.2 Computing correlation
The correlation coefficient can’t account for any relationships that aren’t linear, regardless of strength.
# between -1~1
cor(df$x, df$y)
# To ignore data points where one or both values are missing
cor(df$x, df$y, use = "pairwise.complete.obs")6.4.1.3 Relationships between variables
You’ll be working with a dataset world_happiness containing results from the 2019 World Happiness Report. The report scores various countries based on how happy people in that country are. It also ranks each country on various societal aspects such as social support, freedom, corruption, and others. The dataset also includes the GDP per capita and life expectancy for each country.
# Create dataset
world_happiness <- readRDS("data/world_happiness_sugar.rds")
# Create a scatterplot of happiness_score vs. life_exp
ggplot(world_happiness, aes(x = life_exp, y = happiness_score)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)## `geom_smooth()` using formula = 'y ~ x'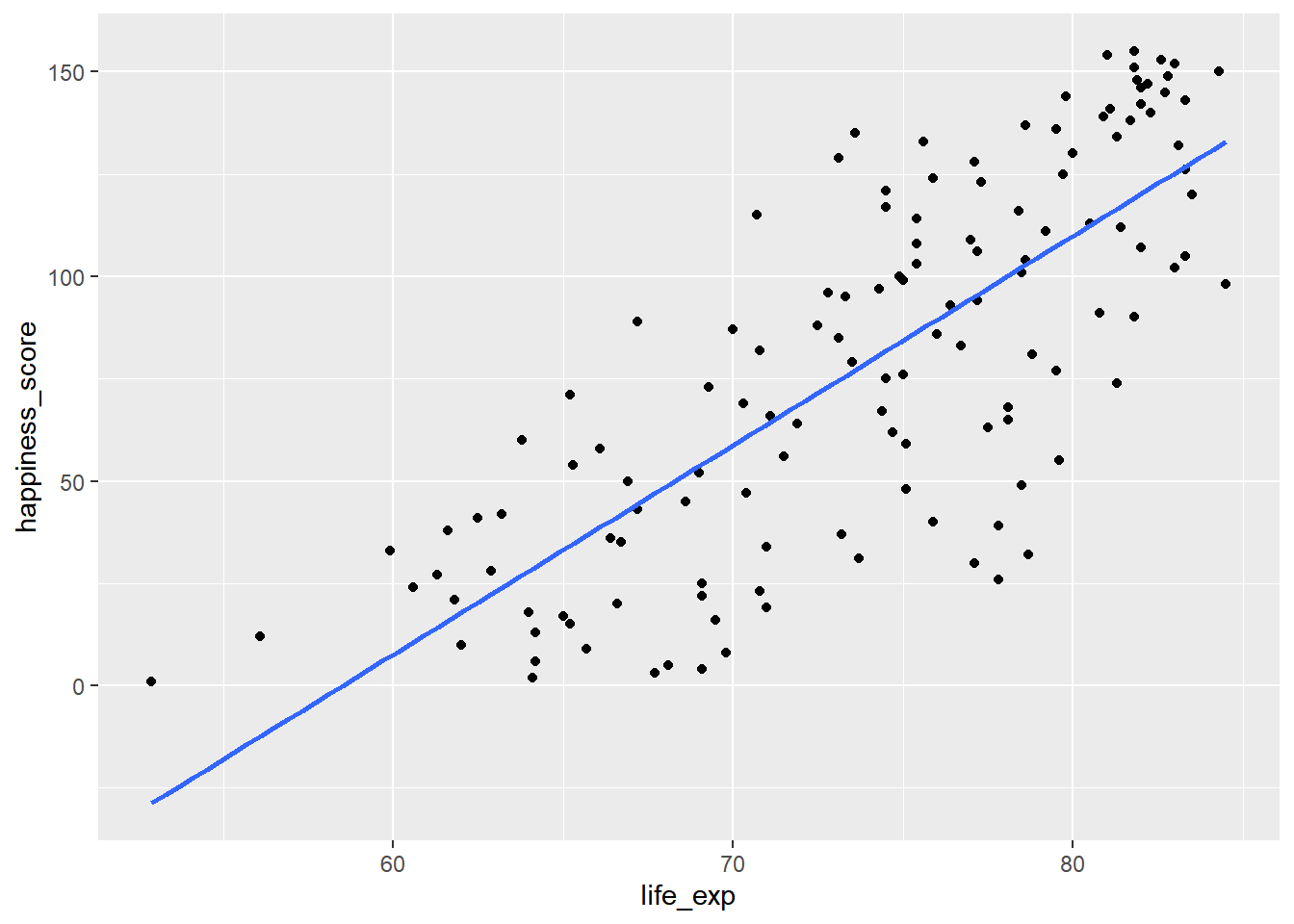
# Correlation between life_exp and happiness_score
cor(world_happiness$life_exp, world_happiness$happiness_score)## [1] 0.77376156.4.2 Correlation caveats
Non-linear relationships: always visualize your data.
Skewed data: transformations
- Log transformation (
log(x)) - Square root transformation (
sqrt(x)) - Reciprocal transformation (
1 / x) - Combinations of these, e.g.:
log(x)andlog(y)sqrt(x)and1 / y
Correlation does not imply causation.
Confounding variables.
# Scatterplot of gdp_per_cap and life_exp
ggplot(world_happiness, aes(x = gdp_per_cap, y = life_exp)) +
geom_point()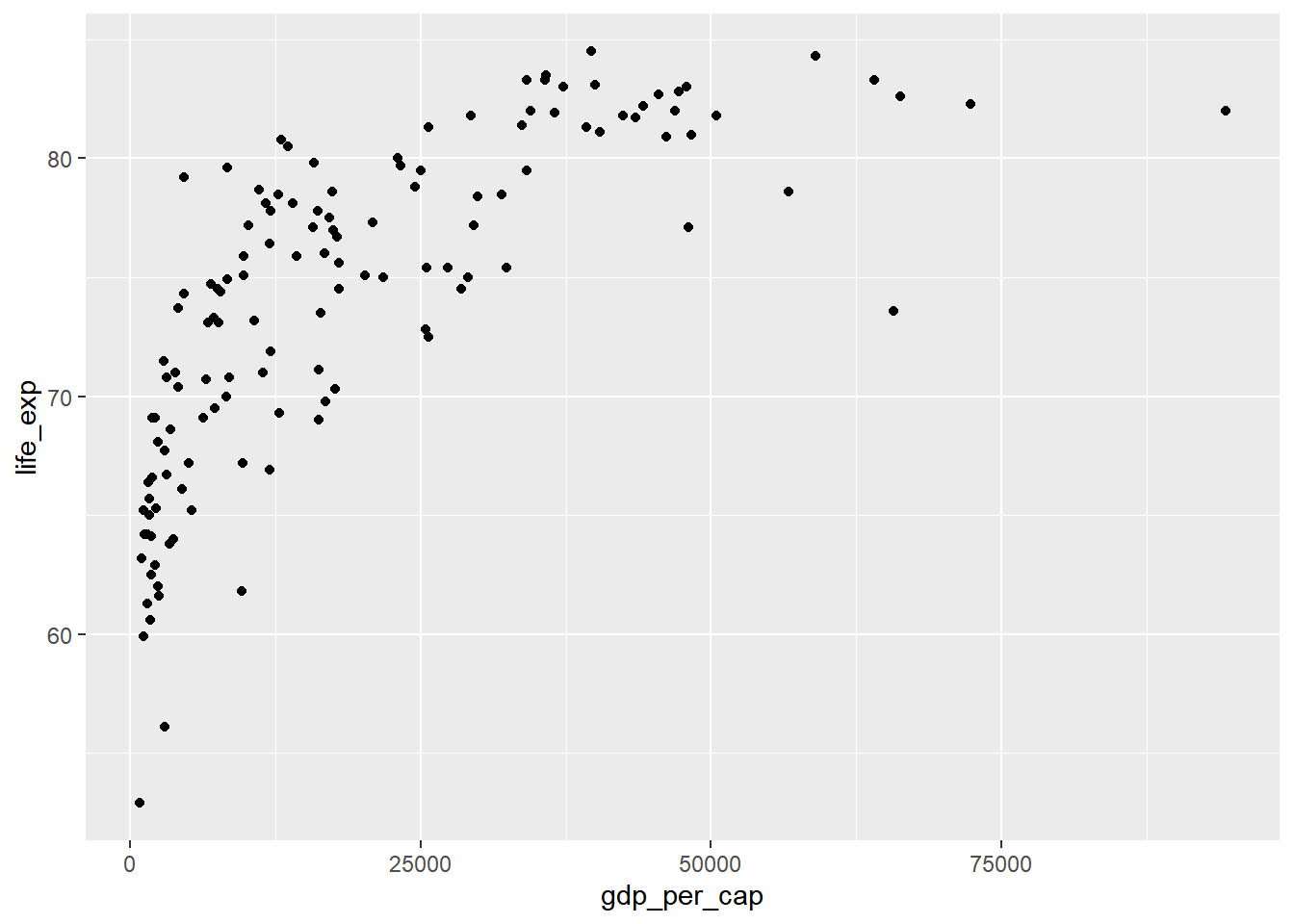
# Correlation between gdp_per_cap and life_exp
cor(world_happiness$gdp_per_cap, world_happiness$life_exp)## [1] 0.7235027Log transformations are great to use on variables with a skewed distribution, such as GDP.
# Create log_gdp_per_cap column
world_happiness <- world_happiness %>%
mutate(log_gdp_per_cap = log(gdp_per_cap))
# Scatterplot of happiness_score vs. log_gdp_per_cap
ggplot(world_happiness, aes(x = log_gdp_per_cap, y = happiness_score)) +
geom_point()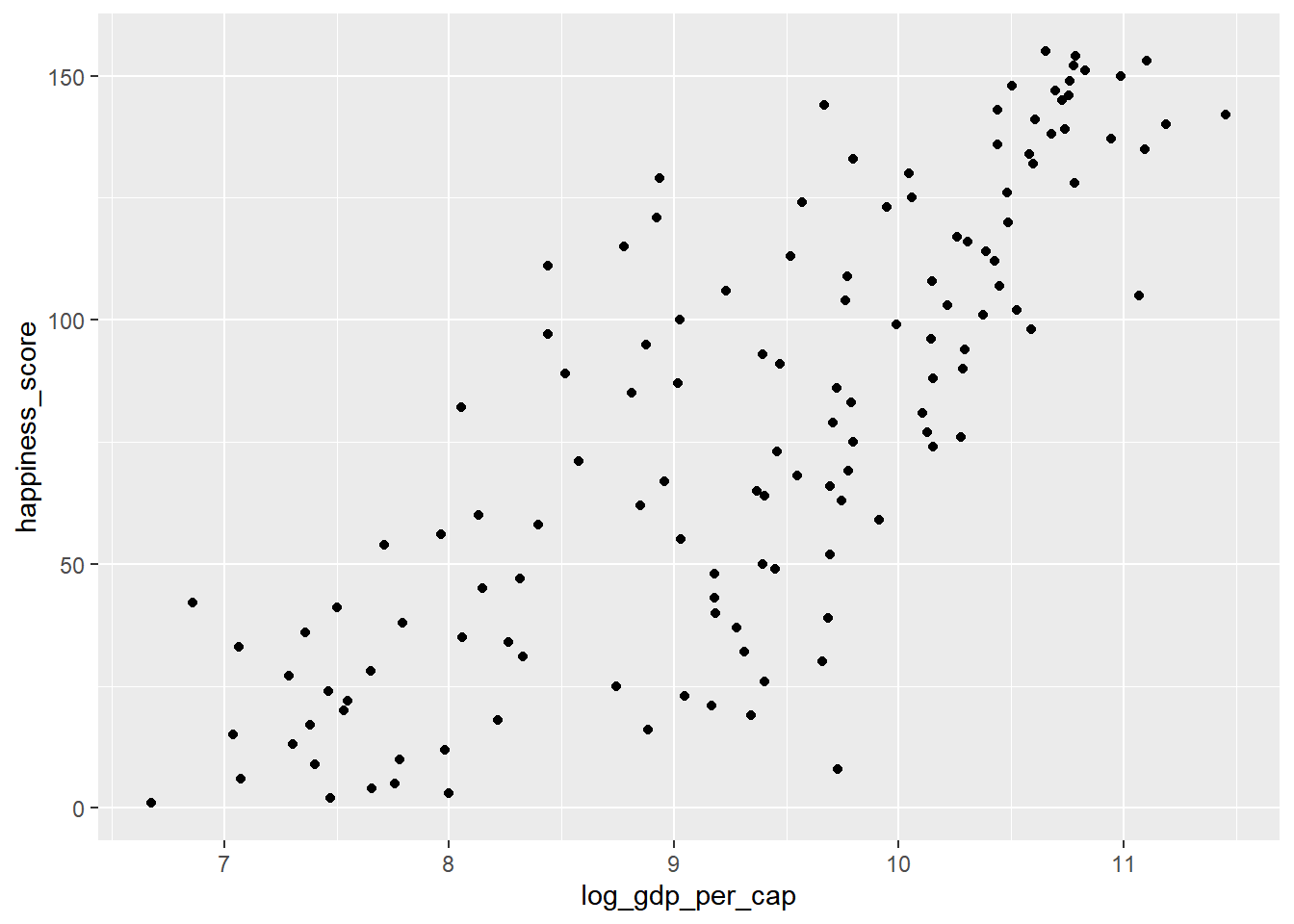
# Calculate correlation
cor(world_happiness$log_gdp_per_cap, world_happiness$happiness_score)## [1] 0.7965484Does sugar improve happiness?
# Scatterplot of grams_sugar_per_day and happiness_score
ggplot(world_happiness, aes(x = grams_sugar_per_day, y = happiness_score)) +
geom_point()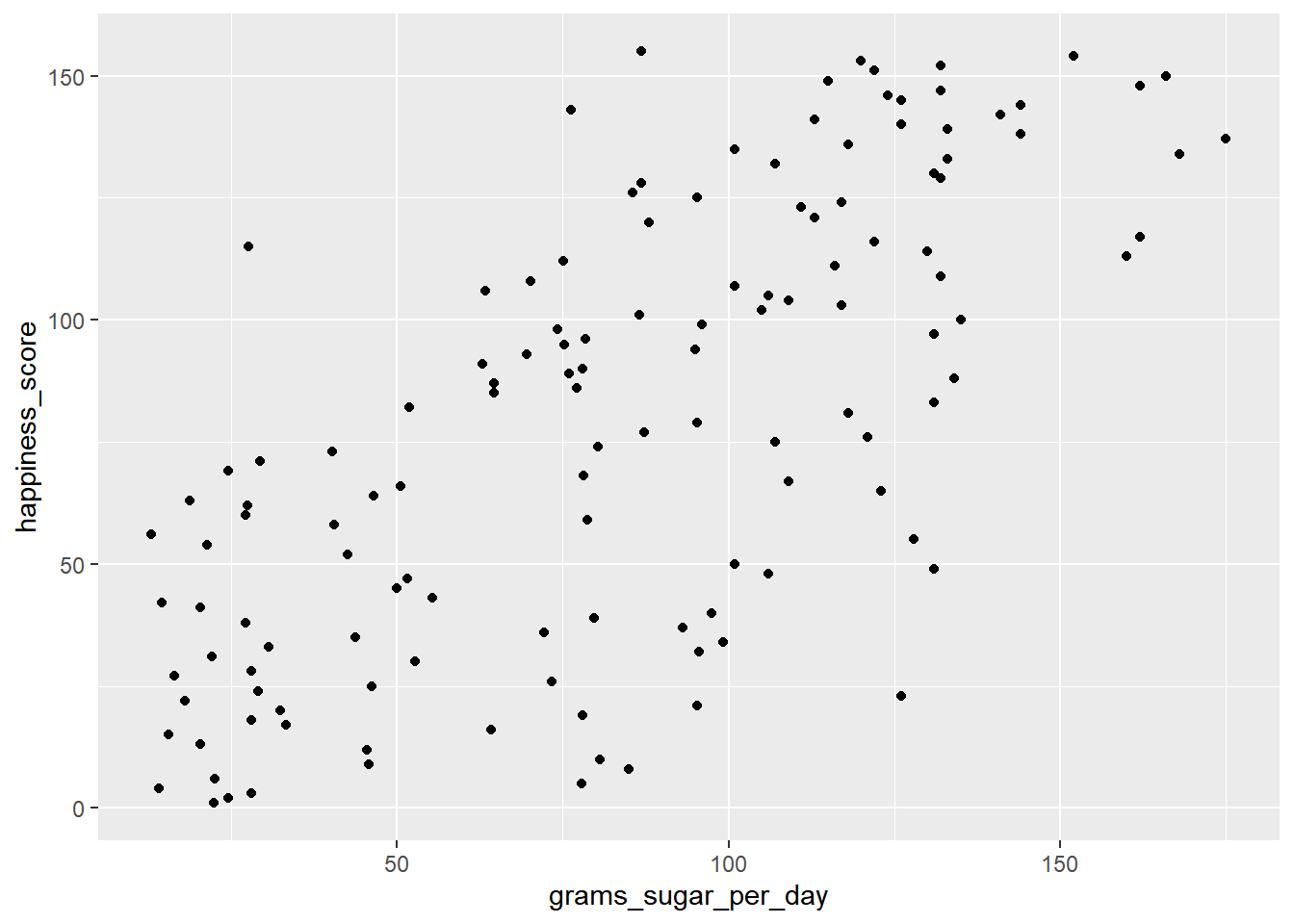
# Correlation between grams_sugar_per_day and happiness_score
cor(world_happiness$happiness_score, world_happiness$grams_sugar_per_day)## [1] 0.69391Increased sugar consumption is associated with a higher happiness score. If correlation always implied that one thing causes another, people may do some nonsensical things, like eat more sugar to be happier.
6.4.3 Design of experiments
- Controlled experiments vs Observational studies
- Gold standard of experiments: randomized controlled trial, placebo, double-blind trial
- Observational: participants are not assigned randomly to groups, establish association not causation
- Longitudinal vs. Cross-sectional studies